Die Digitalisierung alter Bestände ist nichts Neues. Aber der Ansatz, den wir heute besprechen, ist eine kleine Revolution. Wir kombinieren die rohe Kraft etablierter OCR-Engines (Tesseract und PaddleOCR) mit der sprachlichen Intelligenz moderner KI-Modelle, um Ergebnisse zu erzielen, von denen Archivare früher nur träumen konnten.
Die Herausforderung: Warum "Strg+F" bei alten Büchern scheitert
Alte Bücher sind für Computer eine Qual. Die Herausforderungen sind vielfältig:
- Fraktur und Sütterlin: Alte deutsche Schriftarten werden von Standard-OCR oft als Buchstabensalat erkannt.
- Papierqualität: Flecken, "Gilb" und durchscheinende Rückseiten stören die Bilderkennung.
- Layout: Spaltenwechsel, Initialen und Randnotizen verwirren die Lesereihenfolge.
Hier kommen unsere digitalen Werkzeuge ins Spiel.
Schritt 1: Die OCR-Engines im Duell und Duett
Anstatt uns auf eine einzige Lösung zu verlassen, betrachten wir zwei Giganten der Texterkennung.
1. Der Klassiker: Tesseract OCR
Tesseract (ursprünglich von HP, heute von Google gepflegt) ist der Standard in der Open-Source-Welt.
- Stärke: Mit den richtigen Trainingsdaten (z.B. deu_frak für Fraktur) liefert Tesseract extrem solide Ergebnisse bei sauber gescannten Seiten.
- Schwäche: Es tut sich schwer bei komplexen Layouts oder starkem Rauschen im Bildhintergrund.
2. Der Herausforderer: PaddleOCR
PaddleOCR basiert auf Deep Learning (Baidu's PaddlePaddle Framework) und ist ein "Rising Star" in der Szene.
- Stärke: Es ist unglaublich robust gegenüber "wilden" Szenarien. Verzerrte Seiten, ungewöhnliche Schriftarten oder Text vor komplexen Hintergründen werden oft besser erkannt als bei Tesseract.
- Das Besondere: Die Layout-Analyse von PaddleOCR ist oft überlegen, was hilft, Überschriften von Fließtext zu unterscheiden.
- Die Strategie: Viele Entwickler nutzen einen hybriden Ansatz. PaddleOCR wird genutzt, um die Textboxen (Bounding Boxes) zu finden und das Layout zu verstehen, während Tesseract (speziell trainiert auf alte Schriften) den Inhalt dieser Boxen entziffert.
3. Die neue Generation: Mistral OCR (LLM-basiert)
Während Tesseract und PaddleOCR auf Mustererkennung und klassische Computer Vision setzen, nähert sich Mistral dem Problem über Multimodale Large Language Models.
- Stärke: Mistral OCR „liest“ nicht nur Buchstaben, sondern versteht den Kontext. Es ist unschlagbar bei handschriftlichen Notizen, extrem verblichenen Dokumenten oder komplexen Tabellenstrukturen, an denen klassische Algorithmen verzweifeln. Da das Modell semantisches Wissen besitzt, kann es fehlende Buchstaben oder Tippfehler im Original während des Auslesens logisch korrigieren.
- Das Besondere: Die Fähigkeit zur Strukturierung. Mistral liefert nicht nur eine Textwüste, sondern kann das Dokument direkt in sauberes Markdown oder JSON umwandeln. Es erkennt intuitiv, welche Information eine IBAN, ein Datum oder ein Rechnungsbetrag ist.
- Die Strategie: Mistral OCR ist die „Geheimwaffe“ für unstrukturierte Daten. Es wird oft dort eingesetzt, wo Dokumente nicht nur digitalisiert, sondern direkt für die automatisierte Weiterverarbeitung (z.B. in einer Datenbank oder einem ERP-System) aufbereitet werden müssen.
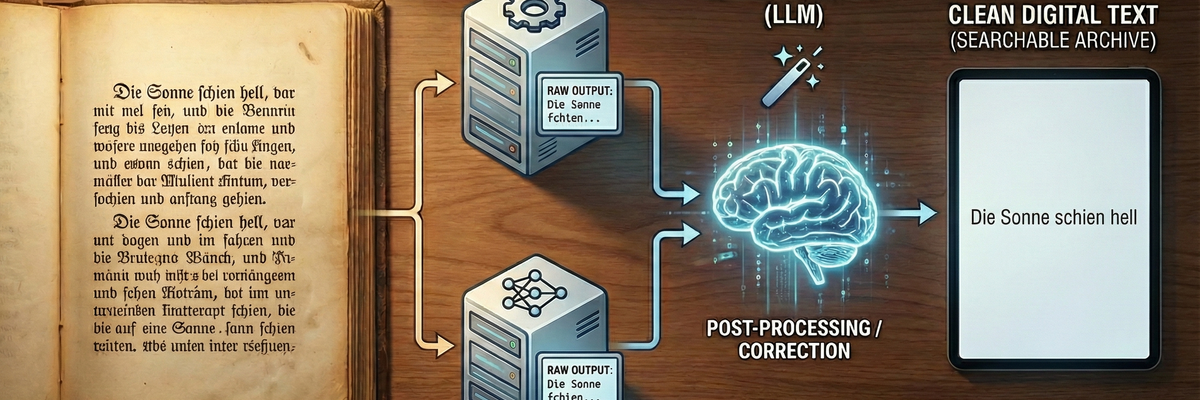
Schritt 2: Der "Game Changer" – Die KI-Optimierung
Selbst die beste OCR macht bei 100 Jahre alten Büchern Fehler. Aus einem „dass“ wird ein „dafs“, aus „König“ ein „Ronig“. Früher musste das mühsam von Hand korrigiert werden.
Heute schalten wir eine LLM (Large Language Model) nach. Wir füttern die rohen, teils fehlerhaften OCR-Ergebnisse in eine KI (wie GPT-4, Claude oder lokale Llama-Modelle) mit einem klaren Auftrag:
"Korrigiere OCR-Fehler, veraltete Rechtschreibung (optional) und Formatierung, aber verändere niemals den inhaltlichen Sinn oder den Stil des Textes."
Das Ergebnis im Vergleich
- Original Scan: „Die Sonne ẜchien hell auf das Waẜẜer.“
- Roh-OCR (Fehler): „Die Sanne fchien beII auf das Wafler.“
- Nach KI-Korrektur: „Die Sonne schien hell auf das Wasser.“
Die KI versteht den Kontext. Sie weiß, dass "Sanne" in diesem Satz keinen Sinn ergibt, "Sonne" aber schon. Sie repariert, was die OCR "falsch gesehen" hat, basierend auf Wahrscheinlichkeiten und Sprachverständnis.
Der Workflow in der Praxis
Wie sieht so eine Pipeline für Entwickler oder Hobby-Archivare aus?
- Preprocessing: Das Bild wird mit OpenCV in Graustufen umgewandelt, der Kontrast erhöht und das Rauschen entfernt (Denoising).
- Engine-Wahl: Ein Python-Skript entscheidet: Ist das Layout komplex? -> PaddleOCR. Ist es eine Standard-Fraktur-Seite? -> Tesseract.
- Texterkennung: Der Text wird extrahiert.
- Post-Processing (AI): Der Textblock wird an die API der KI gesendet.
- Re-Assembly: Der korrigierte Text wird in ein durchsuchbares PDF oder ePub verwandelt.
Fazit: Die Demokratisierung der Archive
Durch die Kombination von Tesseract (für die Präzision bei speziellen Schriften), PaddleOCR (für das Layout-Verständnis), Mistral OCR und generativer KI (für die Fehlerkorrektur) können wir alte Bücher nicht nur digitalisieren, sondern restaurieren.
Das Wissen vergangener Jahrhunderte wird so nicht nur konserviert, sondern wieder zugänglich, durchsuchbar und lebendig gemacht.