Dreamteam LLM & RAG: So funktioniert der AI Bot
Moderne RAG-Technologie, skalierbare Infrastruktur und vollständige Datenkontrolle – eine technisch fundierte Lösung für Unternehmen.
Der rms. AI Bot nutzt eine innovative Architektur, die semantische Einsicht mit generativer KI verbindet. Anhand von Embeddings, Vektordatenbanken und einem leistungsfähigen Sprachmodell generiert er relevante, aktuelle und präzise Antworten – direkt aus Ihren Unternehmensinhalten.
Erfahren Sie, wie unser System aufgebaut ist, welche Technologiekomponenten es nutzt und wie Sie davon profitieren.

Was ist RAG?
Eine Technik, die Inhalte wirklich versteht.
Bei der klassischen Suche werden Worte verglichen. Unsere Lösung geht weiter: Inhalte werden durch sogenannte Embeddings in Vektoren umgewandelt und in einer Vektordatenbank gespeichert – zum Beispiel in ChromaDB, Pinecone, Milvus oder Faiss. Wenn eine Frage gestellt wird, wird sie ebenfalls eingebettet und mit den relevantesten Dokumenten abgeglichen — die besten Inhalte dienen dann als Kontext für ein Sprachmodell, das die finale Antwort erzeugt.
Vorteile im Überblick:
Sicherheit & Datenschutz: Ihre Daten bleiben in Ihrer Datenbank-Umgebung – kein externes Training.
Kosten- & Ressourceneffizienz: Kein aufwändiges Fine-Tuning nötig – schneller, kostengünstiger.
Aktualität & Verlässlichkeit: Antworten basieren auf aktuellen Daten.
Flexibilität: Änderungen an Datenquellen möglich, ohne Modell neu trainieren zu müssen.
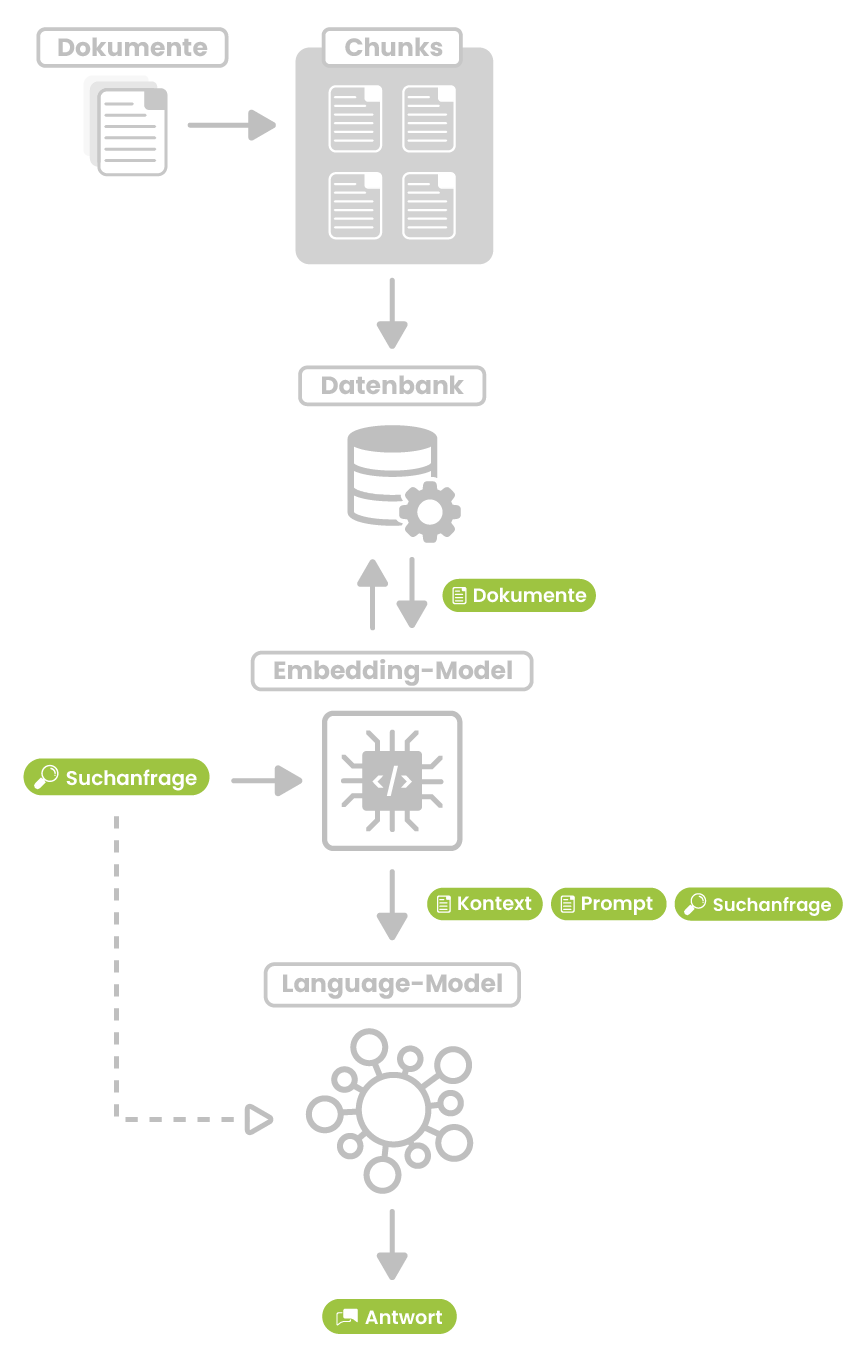
Wie werden die Daten in einem RAG-System gespeichert?

Hier werden zuerst alle verfügbaren Daten in sogenannte numerische Vektoren umgewandelt, die die semantische Bedeutung der Inhalte erfassen und in dafür geeigneten Datenbanken, sogenannten Vektordatenbanken, gespeichert. Beispiele hierfür sind z. B. Chroma, Pinecone, Faiss, Elasticsearch oder Milvus. Die Vektordatenbanken ermöglichen eine semantische Ähnlichkeitssuche, das heißt, sie finden Inhalte, die inhaltlich oder kontextuell ähnlich zur Suchanfrage sind, auch wenn die exakten Wörter nicht übereinstimmen. Dies ist vergleichbar mit Anwendungen wie der Suche nach ähnlichen Bildern oder der Erkennung eines Liedes in Shazam durch Vorsingen. Im RAG-Prozess wird bei einer Nutzeranfrage die Vektordatenbank nach den relevantesten Dokumenten durchsucht. Diese Dokumente werden dann als Kontext verwendet, um die Antwort des LLM informativer und genauer zu machen. Dadurch werden die Einschränkungen von LLMs in Bezug auf Wissensaktualität und Quellenangaben deutlich reduziert. Das RAG-System des rms. AI Bots wird auf einem rms. eigenen Cloudserver betrieben.
Vorteile von RAG

Sicherheit und Datenschutz
Bei RAG verbleiben firmeneigene Daten in der gesicherten Datenbankumgebung, was strengere Zugriffskontrollen ermöglicht. Beim Fine-Tuning werden die Daten ins Modelltraining integriert, was potenziell zu breiterem Datenzugriff führen kann.

Kosten- und Ressourceneffizienz
Fine-Tuning ist rechenintensiv und zeitaufwendig, da es umfangreiche Trainingsphasen und Datenaufbereitung erfordert. RAG vermeidet diesen Trainingsaufwand, indem es die Daten dynamisch abruft, was kostengünstiger und schneller skalierbar ist.

Aktualität und Zuverlässigkeit
RAG kann stets auf aktuelle Daten zugreifen und somit präzisere und vertrauenswürdigere Antworten liefern. Fine-Tuning basiert auf einem statischen Trainingsdatensatz und kann veraltetes Wissen enthalten.

Flexibilität
RAG eignet sich besonders gut für Anwendungen, bei denen sich die zugrunde liegenden Daten häufig ändern oder erweitert werden, ohne dass das Modell neu trainiert werden muss. Fine-Tuning ist besser für sehr spezifische, eng umrissene Aufgaben, erfordert aber bei jeder Datenänderungen ein erneutes Training.
Ablauf einer RAG-Suche

Eingabe der Frage
Der Besucher gibt eine Frage oder Suchanfrage in das System ein.

Vektorisierung der Frage
Die Frage wird durch ein sogenanntes Embedding-Modell in einen Vektor umgewandelt, der die semantische Bedeutung der Frage repräsentiert.

Semantische Ähnlichkeitssuche
Die Vektordatenbank wird mit dem Fragevektor abgefragt, um die semantisch ähnlichsten Dokumente oder Textpassagen zu finden.

Ausgabe der relevantesten Ergebnisse
Die X relevantesten Dokumente (z. B. Top 5 oder Top 10) werden aus der Vektordatenbank zurückgegeben.
-> Optional kann ein Reranker eingebunden werden, der die Präzision der Ergebnisse um bis zu 35% verbessert.

Kombination von Frage, Kontext und Prompt
Die ursprüngliche Frage, die gefundenen Dokumente und ein Prompt (Aufgabenstellung) werden an das Sprachmodell (LLM) übergeben.

Verarbeitung durch das Sprachmodell
Das LLM generiert basierend auf der Frage und den Kontextinformationen eine Antwort.

Ausgabe der Antwort
Die generierte Antwort wird dem Nutzer präsentiert. Bei Bedarf werden Links zu relevanten Quellen/Seiten hinzugefügt.