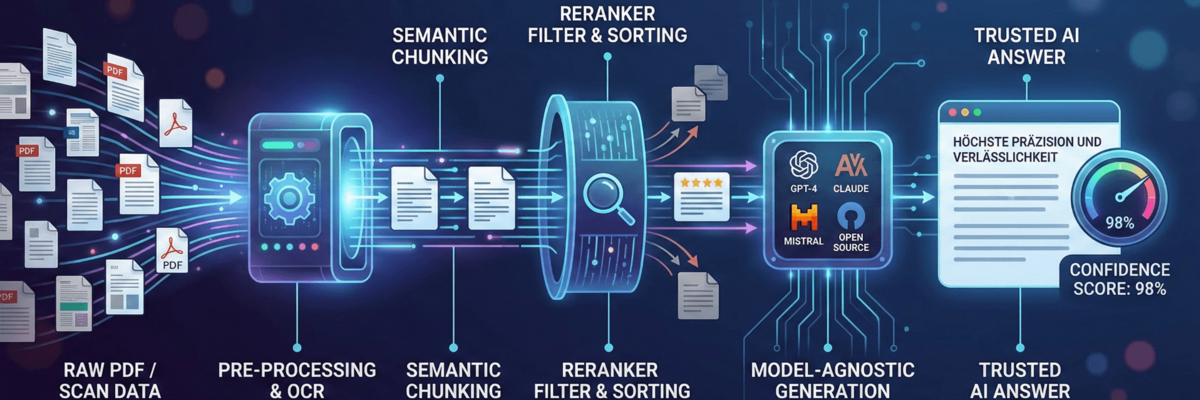
It is the result of a highly complex chain of processing steps - the so-called architecture. If you want to integrate AI productively and reliably into business processes today, you have to move away from the idea of simply "throwing a document into a chatbot". We provide an insight into the technical standards that we have implemented to minimize hallucinations and guarantee maximum reliability.
1. the basis: not all data is the same
Before an AI can answer a question, it must "understand" the available information. The biggest hurdle here is often unstructured data sources such as complex PDFs or scans.
- Precise OCR (Optical Character Recognition): We rely on a combination of PaddleOCR and Tesseract, supported by the Mistral AI Optimizer. The aim is not only to recognize text, but also to correctly interpret table structures and layouts. A slipped value in a table can otherwise falsify the entire answer.
- Semantic & contextual chunking: Conventional systems truncate texts after a certain number of characters. We use semantic chunking to divide texts into logical sections. With PDFs in particular, we pay attention to the context: A paragraph from chapter 4 retains its affiliation to the heading so that the meaning is not lost during "retrieval".
2 The filter: relevance through reranking
A common problem with AI searches (RAG) is noise. A vector search often returns documents that sound similar in terms of language but are not relevant to the topic. This is where we use a so-called reranker. You can think of it as an expert who critically reviews the top results returned by the quick search and sorts them according to their actual relevance to the user's question. Only what really has substance is sent to the language model for the final answer.
3. quality assurance: the confidence score
One of the biggest risks with LLMs is the so-called hallucination - the self-confident invention of facts. To counteract this, we have integrated an evaluation system: the Confidence Score. Each generated answer is evaluated on the basis of the underlying sources. If the score is below a defined threshold, the system transparently indicates this or refuses to answer instead of taking a risk. This honesty of the machine is more important in a professional context than quick but incorrect information.
4 Sovereignty through model agnosticism
The world of language models is changing rapidly. What is the standard today (such as GPT-4 or Claude 3) may be overtaken tomorrow by a highly efficient open source model. Our architecture is deliberately model-agnostic. We integrate all common language models, including powerful open source alternatives. This offers two decisive advantages:
- Future-proofing: we can switch to the best available model at any time.
- Data sovereignty: Specialized open source models in secure environments can be used for highly sensitive data.
Conclusion: quality is a question of architecture
The "intelligence" of an AI solution lies less in the name of the model and more in the care taken in data preparation and the rigor of quality control. By combining semantic chunking, intelligent reranking and transparent confidence values, we create tools that don't just chat, but work precisely.
A look into the future
Although this stack is already at the cutting edge of technology, we are constantly evaluating further approaches. Topics such as hybrid search (the combination of keyword and meaning search) or GraphRAG, which maps relationships between information even better, are the next logical steps for us on the way to the perfect answer.