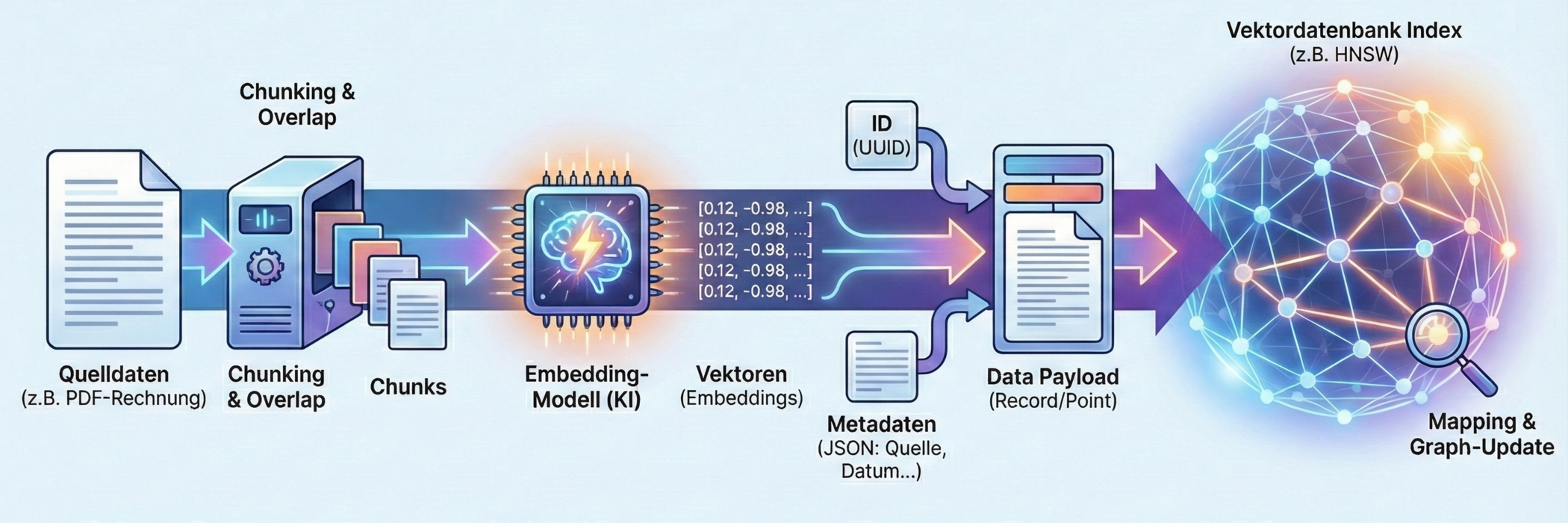
Here is the process step by step in detail:
1. data preparation & chunking (fragmentation)
Before data even comes close to the database, it must be prepared. AI models have a context limit (token limit). You can't turn an entire 500-page book into a single vector at once, as the "mean meaning" of an entire book would be too diluted.
- The process: The text (or data) is broken down into smaller sections called chunks.
- Strategy: A chunk could be 500 words, for example.
- Overlap: Important. Do not cut hard. Chunk 1 goes from word 1-500, chunk 2 from word 450-950. This overlap of 50 words ensures that the context is not lost if an important sentence is right at the intersection.
2. vectorization (embedding creation)
This is the crucial step. The created chunks are now sent to the embedding model (e.g. OpenAI text-embedding-3, Cohere, or a local model).
- Input: The text chunk ("The dog chases the cat...").
- Process: The model performs an inference. It analyzes the semantic meaning.
- Output: The model returns the vector (e.g. a list of 1536 floating point numbers).
- Duration: This is often the slowest part of the pipeline, depending on the speed of the API or the local GPU.
3. merging the "data payload"
Not only the vector is written to the database. An entry in a vector database (often called a "record" or "point") usually consists of three parts:
- ID: A unique identifier (UUID).
- The vector: The series of numbers [0.12, -0.98, ...].
- Metadata (JSON): This is extremely important. This is where you store the original text, the source (e.g. "Page 12, Manual.pdf"), the author or the date. Without metadata, the database would later know that a vector matches, but would not be able to display the text.
4. indexing - the writing process
Now the data is actually "written" to the database (often referred to as an upsert - update/insert). Unlike SQL, where the row is simply appended at the bottom, the vector database must sort the new vector into its mathematical index.
- Mapping: The database looks at the new vector and calculates where it is located in the high-dimensional space.
- Graph update (for HNSW): If an HNSW index is used, the database must draw connections (edges) to the nearest neighbors. The new point is therefore immediately integrated into the "road network" of the existing data.
- Effort: This is computationally intensive. This is why many vector databases (such as Pinecone or Weaviate) support asynchronous indexing. The data is only searchable once it has been integrated into the index (which usually only takes milliseconds to seconds).
Summary using the example of
Imagine you are uploading a PDF invoice:
- Extract: A script extracts the raw text from the PDF.
- Chunk: The text is split into 3 paragraphs.
- Embed: The 3 paragraphs are sent to the AI -> 3 vectors are returned.
- Upsert: The database saves the 3 vectors and notes in the metadata: "Belongs to invoice_2023.pdf".
- Index: The database links these vectors internally with other vectors that deal with topics such as "Costs", "Payment" or "Taxes".
Are you planning to build such a pipeline yourself and need support? Then please contact us.