The digitization of old collections is nothing new. But the approach we are discussing today is a small revolution. We combine the raw power of established OCR engines (Tesseract and PaddleOCR) with the linguistic intelligence of modern AI models to achieve results that archivists could only dream of in the past.
The challenge: Why "Ctrl+F" fails with old books
Old books are a pain for computers. The challenges are manifold:
- Fraktur and Sütterlin: old German fonts are often recognized by standard OCR as a jumble of letters.
- Paper quality: stains, "yellowing" and translucent backsides interfere with image recognition.
- Layout: Column changes, initials and marginal notes confuse the reading order.
This is where our digital tools come into play.
Step 1: The OCR engines in duel and duet
Instead of relying on a single solution, let's look at two giants of text recognition.
1. the classic: Tesseract OCR
Tesseract (originally from HP, now maintained by Google) is the standard in the open source world.
- Strength: With the right training data (e.g. deu_frak for Fraktur), Tesseract delivers extremely solid results with cleanly scanned pages.
- Weakness: It struggles with complex layouts or strong noise in the image background.
2. the challenger: PaddleOCR
PaddleOCR is based on deep learning (Baidu's PaddlePaddle Framework) and is a rising star in the scene.
- Strength: It is incredibly robust against "wild" scenarios. Distorted pages, unusual fonts or text in front of complex backgrounds are often recognized better than with Tesseract.
- Special feature: PaddleOCR's layout analysis is often superior, which helps to distinguish headings from body text.
- The strategy: Many developers use a hybrid approach. PaddleOCR is used to find the text boxes (bounding boxes) and understand the layout, while Tesseract (specially trained on old fonts) deciphers the content of these boxes.
3. the new generation: Mistral OCR (LLM-based)
While Tesseract and PaddleOCR rely on pattern recognition and classic computer vision, Mistral approaches the problem using multimodal large language models.
- Strength: Mistral OCR not only "reads" letters, but also understands the context. It is unbeatable when it comes to handwritten notes, extremely faded documents or complex table structures, where classic algorithms despair. As the model has semantic knowledge, it can logically correct missing letters or typing errors in the original during the reading process.
- The special feature: The ability to structure. Mistral doesn't just deliver a wasteland of text, but can convert the document directly into clean Markdown or JSON. It intuitively recognizes which information is an IBAN, a date or an invoice amount.
- The strategy: Mistral OCR is the "secret weapon" for unstructured data. It is often used where documents not only need to be digitized, but also prepared directly for automated further processing (e.g. in a database or ERP system).
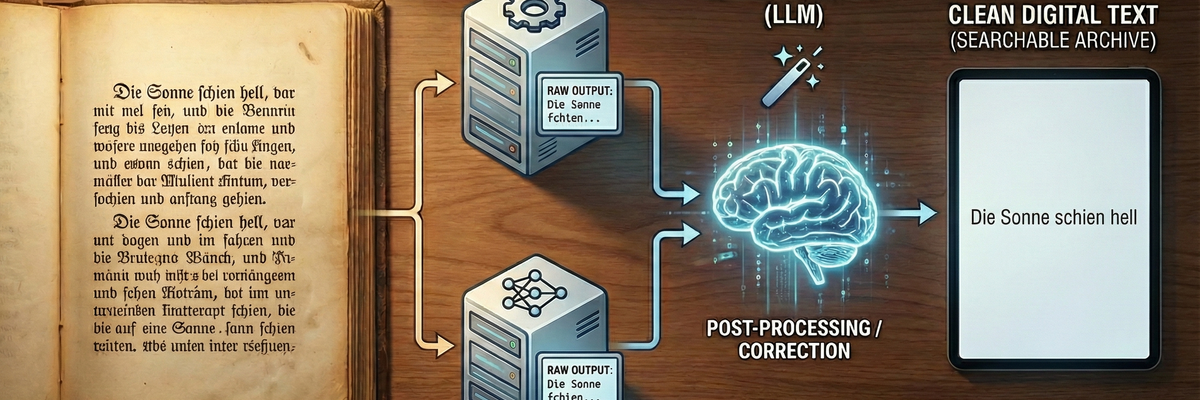
Step 2: The "game changer" - AI optimization
Even the best OCR makes mistakes with 100-year-old books. A "dass" becomes a "dafs", a "König" becomes a "Ronig". In the past, this had to be laboriously corrected by hand.
Today, we use an LLM (Large Language Model). We feed the raw, sometimes incorrect OCR results into an AI (such as GPT-4, Claude or local Llama models) with a clear task:
"Correct OCR errors, outdated spelling (optional) and formatting, but never change the meaning or style of the text."
The result in comparison
- Original scan: "The sun shone brightly on the waẜẜer."
- Raw OCR (error): "The sun shone brightly on the wafler."
- After AI correction: "The sun shone brightly on the water."
The AI understands the context. It knows that "Sanne" makes no sense in this sentence, but "Sonne" does. It fixes what the OCR "saw wrong" based on probabilities and language understanding.
The workflow in practice
What does a pipeline like this look like for developers or amateur archivists?
- Preprocessing: The image is converted to greyscale with OpenCV, the contrast is increased and noise is removed (denoising).
- Engine selection: A Python script decides: Is the layout complex? -> PaddleOCR. Is it a standard fracture page? -> Tesseract.
- Text recognition: The text is extracted.
- Post-processing (AI): The text block is sent to the AI's API.
- Re-assembly: The corrected text is converted into a searchable PDF or ePub.
Conclusion: The democratization of archives
By combining Tesseract (for precision with special fonts), PaddleOCR (for layout understanding), Mistral OCR and generative AI (for error correction), we can not only digitize old books, but also restore them.
The knowledge of past centuries is thus not only preserved, but made accessible, searchable and alive again.