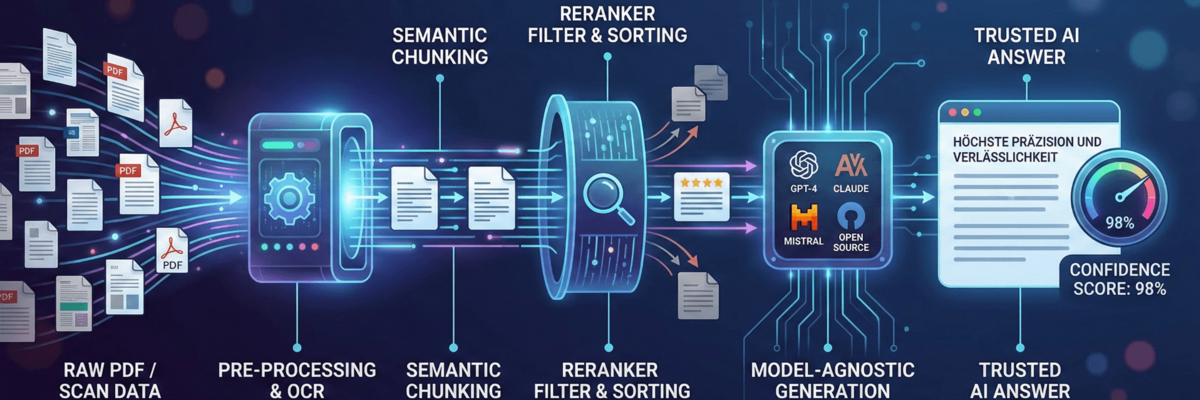
Sie ist das Ergebnis einer hochkomplexen Kette von Verarbeitungsschritten – der sogenannten Architektur. Wer heute KI produktiv und verlässlich in Unternehmensprozesse integrieren will, muss sich von der Idee lösen, einfach nur ein „Dokument in einen Chatbot zu werfen“. Wir geben einen Einblick in die technischen Standards, die wir implementiert haben, um Halluzinationen zu minimieren und maximale Verlässlichkeit zu garantieren.
1. Die Basis: Daten sind nicht gleich Daten
Bevor eine KI eine Frage beantworten kann, muss sie die vorliegenden Informationen „verstehen“. Die größte Hürde sind hierbei oft unstrukturierte Datenquellen wie komplexe PDFs oder Scans.
- Präzises OCR (Optical Character Recognition): Wir setzen auf eine Kombination aus PaddleOCR und Tesseract, unterstützt durch den Mistral AI Optimizer. Das Ziel ist es, nicht nur Text zu erkennen, sondern auch Tabellenstrukturen und Layouts korrekt zu interpretieren. Ein verrutschter Wert in einer Tabelle kann sonst die gesamte Antwort verfälschen.
- Semantic & Contextual Chunking: Klassische Systeme schneiden Texte stumpf nach einer bestimmten Zeichenzahl ab. Wir nutzen Semantic Chunking, um Texte in logische Sinnabschnitte zu unterteilen. Speziell bei PDFs achten wir auf den Kontext: Ein Absatz aus Kapitel 4 behält seine Zugehörigkeit zur Überschrift, damit die Bedeutung beim „Wiederfinden“ (Retrieval) nicht verloren geht.
2. Der Filter: Relevanz durch Reranking
Ein häufiges Problem bei KI-Suchen (RAG) ist das Rauschen. Eine Vektorsuche liefert oft Dokumente, die zwar sprachlich ähnlich klingen, aber inhaltlich am Thema vorbeigehen. Hier setzen wir einen sogenannten Reranker ein. Man kann ihn sich wie einen Experten vorstellen, der die von der schnellen Suche gelieferten Top-Ergebnisse noch einmal kritisch prüft und nach ihrer tatsächlichen Relevanz für die Nutzerfrage sortiert. Nur was wirklich Substanz hat, gelangt zur finalen Beantwortung an das Sprachmodell.
3. Die Qualitätssicherung: Der Confidence Score
Eines der größten Risiken bei LLMs ist die sogenannte Halluzination – das selbstbewusste Erfinden von Fakten. Um dem entgegenzuwirken, haben wir ein Bewertungssystem integriert: den Confidence Score. Jede generierte Antwort wird auf Basis der zugrunde liegenden Quellen bewertet. Liegt der Score unter einem definierten Schwellenwert, weist das System transparent darauf hin oder verweigert die Antwort, statt ein Risiko einzugehen. Diese Ehrlichkeit der Maschine ist im professionellen Kontext wichtiger als eine schnelle, aber falsche Information.
4. Souveränität durch Modell-Agnostik
Die Welt der Sprachmodelle wandelt sich rasant. Was heute der Standard ist (wie GPT-4 oder Claude 3), kann morgen von einem hocheffizienten Open-Source-Modell überholt werden. Unsere Architektur ist bewusst modell-agnostisch aufgebaut. Wir binden alle gängigen Sprachmodelle inklusive leistungsstarker Open-Source-Alternativen ein. Das bietet zwei entscheidende Vorteile:
- Zukunftssicherheit: Wir können jederzeit auf das beste verfügbare Modell wechseln.
- Datensouveränität: Für hochsensible Daten können spezialisierte Open-Source-Modelle in abgesicherten Umgebungen genutzt werden.
Fazit: Qualität ist eine Frage der Architektur
Die „Intelligenz“ einer KI-Lösung steckt weniger im Namen des Modells, sondern vielmehr in der Sorgfalt der Datenaufbereitung und der Strenge der Qualitätskontrolle. Durch die Kombination von semantischem Chunking, intelligentem Reranking und transparenten Confidence-Werten schaffen wir Werkzeuge, die nicht nur chatten, sondern präzise arbeiten.
Ein Blick in die Zukunft
Obwohl dieser Stack bereits zur technologischen Spitze gehört, evaluieren wir kontinuierlich weitere Ansätze. Themen wie Hybrid Search (die Kombination aus Schlagwort- und Bedeutungssuche) oder GraphRAG, das Beziehungen zwischen Informationen noch besser abbildet, sind für uns die nächsten logischen Schritte auf dem Weg zur perfekten Antwort.