Die Herausforderung: Man stellt eine spezifische Frage zu einem komplexen B2B-Produkt und erhält als Antwort den Link zur Startseite der FAQ. Frustrierend. Ineffizient. Generisch. Die nächste Generation von KI-Assistenten im Unternehmen gibt sich damit nicht zufrieden. Sie verstehen nicht nur die Frage, sondern auch, wer sie stellt, in welchem Kontext und für welchen Anwendungsfall. Das Ziel: Ein Vertriebsleiter erhält auf die Frage "Wie ist die Performance?" eine andere Antwort als ein IT-Administrator oder ein Endkunde. Das Ergebnis sind individuell passgenaue Informationen statt generischer Textbausteine.
Doch wie funktioniert das? Wie verwandelt man ein statisches Sprachmodell (LLM), das im Grunde nur Wahrscheinlichkeiten für das nächste Wort berechnet, in einen kontextsensitiven Experten?
Die Antwort liegt nicht in einem einzigen "Zauber-Algorithmus", sondern in einer ausgeklügelten Architektur, die verschiedene technische Komponenten orchestriert. Wir werfen einen Blick unter die Motorhaube unserer Personalisierungs-Engine.
Das Fundament: Die multidimensionale Kontext-Engine
Ein herkömmlicher Chatbot sieht oft nur den aktuellen "Prompt" (die Eingabe). Ein personalisierter Bot hingegen agiert in einem dreidimensionalen Raum aus Nutzer-Identität, Situations-Kontext und Unternehmenswissen.
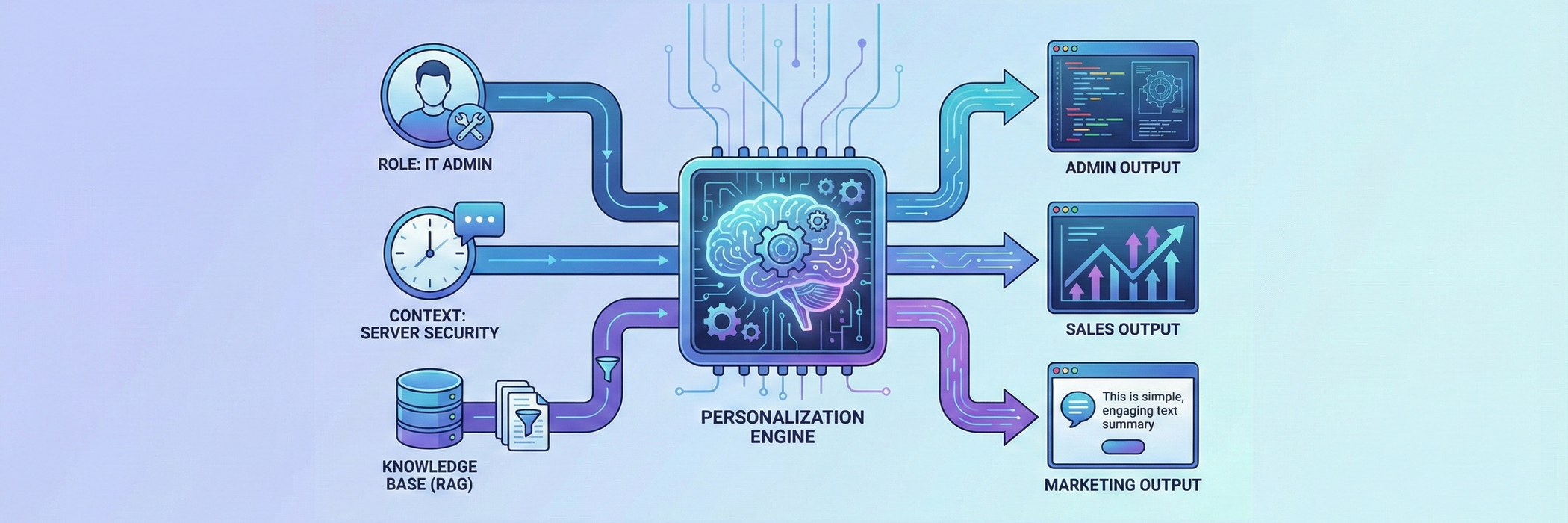
Um dynamische Antworten zu generieren, müssen drei technische Säulen nahtlos ineinandergreifen, bevor das eigentliche Sprachmodell (LLM) überhaupt eine Antwort formuliert.
- Säule 1: Identity & Role Awareness (Das "Wer"). Die Basis jeder Personalisierung ist das Wissen über den Anfragenden. Technisch bedeutet dies eine tiefe Integration in das Identity and Access Management (IAM) des Unternehmens (z.B. Active Directory, Okta). Der Chatbot weiß nicht nur den Namen des Nutzers, sondern kennt dessen Rolle, Abteilung und Berechtigungsstufe. Diese Metadaten werden bei jeder Anfrage "unsichtbar" mitgeführt. Der technische Hebel: Diese Metadaten dienen als Filter (Pre-Filtering) für die Wissensbasis. Ein "Junior Sales Agent" hat technisch keinen Zugriff auf die Dokumente im Index, die für "C-Level Executives" markiert sind. Das LLM kann keine Informationen preisgeben, die es gar nicht erst "sehen" darf.
- Säule 2: Conversational Memory & Situational Context (Das "Jetzt"). Personalisierung bedeutet auch, sich zu erinnern. Ein Nutzer sollte nicht in jeder Nachricht neu erklären müssen, worum es geht. Technisch lösen wir dies über Vektordatenbanken (Vector Stores) als Langzeitgedächtnis und spezialisierte Session-Handler als Kurzzeitgedächtnis. Der Bot speichert den bisherigen Konversationsverlauf nicht nur als Text, sondern als semantische Vektoren (Bedeutungsträger). Wenn ein Nutzer fragt: "Und wie sieht es im Vergleich zum Vorjahr aus?", versteht der Bot durch den gespeicherten Kontext, worauf sich "es" bezieht (z.B. den Umsatz in Region DACH, über den gerade gesprochen wurde).
- Säule 3: Advanced Retrieval-Augmented Generation (RAG) (Das "Was"). Dies ist das Herzstück der dynamischen Inhalte. RAG ist die Technik, bei der das LLM nicht nur auf sein antrainiertes Wissen zurückgreift, sondern aktiv externe, unternehmensspezifische Dokumente durchsucht, um eine Antwort zu generieren. Für echte Personalisierung reicht "Standard-RAG" jedoch nicht aus. Wir nutzen kontextbasiertes RAG. Der Prozess sieht vereinfacht so aus:
- Die Anfrage kommt rein: "Wie ändere ich die Konfiguration?"
- Kontext-Anreicherung: Das System erkennt: Der Nutzer ist "IT-Admin" (Rolle), er befindet sich im Modul "Server-Security" (Anwendungsfall) und hat vorher nach Firewall-Regeln gefragt (Historie).
- Gezieltes Retrieval: Das System sucht nun in der Wissensdatenbank nicht generell nach "Konfiguration ändern", sondern spezifisch nach Dokumenten, die für IT-Admins im Bereich Server-Security relevant sind.
- Dynamisches Prompting: Jetzt passiert die Magie. Das System baut einen komplexen Befehl (Prompt) für das LLM zusammen. Dieser sieht für das Modell etwa so aus:
- „Du bist ein technischer Assistent. Antworte dem Nutzer (Rolle: IT-Admin) auf seine Frage zur Konfiguration im Kontext von Server-Security. Nutze NUR die folgenden drei technischen Dokumente als Quelle [Dokument A, B, C]. Formuliere die Antwort technisch präzise und fasse dich kurz, wie es ein Admin erwartet.“
- Wäre die gleiche Frage von einem Marketing-Manager gekommen, hätte das System andere Dokumente abgerufen und dem LLM im Prompt befohlen, die Antwort "leicht verständlich und nutzenorientiert" zu formulieren.
Das Ergebnis: Maßgeschneiderte Relevanz
Durch die Kombination von Rollenbewusstsein, Konversationsgedächtnis und kontextgesteuertem RAG ändert sich die Art und Weise, wie Informationen konsumiert werden, fundamental. Es geht nicht mehr darum, ob der Bot eine Antwort findet, sondern wie er sie präsentiert. Der technische Hintergrund mag komplex sein, aber das Ziel ist simpel: Dem Nutzer genau die Information zu geben, die er jetzt gerade braucht – in der Sprache, die er versteht.
Das ist der Unterschied zwischen einer Suchmaschine mit Chat-Fenster und einem echten digitalen Kollegen.