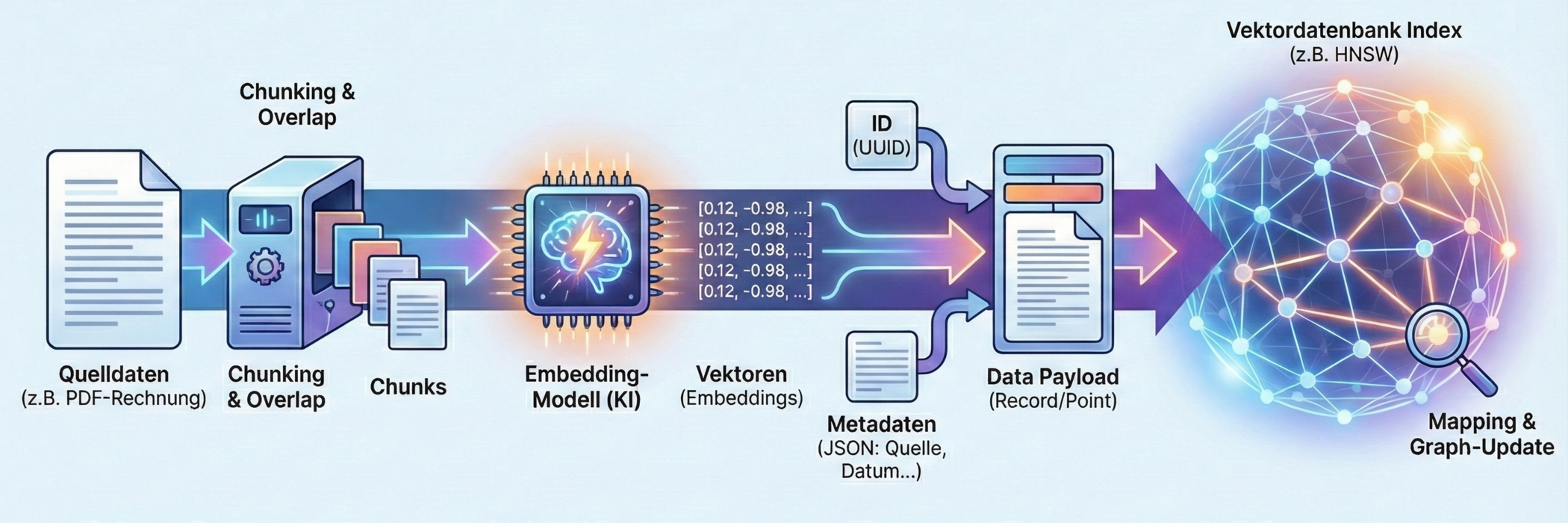
Hier ist der Ablauf Schritt für Schritt im Detail:
1. Datenaufbereitung & Chunking (Zerstückelung)
Bevor Daten überhaupt in die Nähe der Datenbank kommen, müssen sie vorbereitet werden. KI-Modelle haben ein Kontext-Limit (Token-Limit). Man kann nicht ein ganzes 500-seitiges Buch auf einmal in einen einzigen Vektor verwandeln, da die "mittlere Bedeutung" eines ganzen Buches zu verwässert wäre.
- Der Prozess: Der Text (oder die Daten) wird in kleinere Abschnitte, sogenannte Chunks, zerteilt.
- Strategie: Ein Chunk könnte z. B. 500 Wörter umfassen.
- Overlap (Überlappung): Wichtig! Man schneidet nicht hart ab. Chunk 1 geht von Wort 1–500, Chunk 2 von Wort 450–950. Diese Überlappung von 50 Wörtern stellt sicher, dass der Kontext nicht verloren geht, falls ein wichtiger Satz genau an der Schnittstelle steht.
2. Vektorisierung (Embedding Creation)
Dies ist der entscheidende Schritt. Die erstellten Chunks werden nun an das Embedding-Modell (z. B. OpenAI text-embedding-3, Cohere, oder ein lokales Modell) gesendet.
- Input: Der Text-Chunk ("Der Hund jagt die Katze...").
- Prozess: Das Modell führt eine Inferenz durch. Es analysiert die semantische Bedeutung.
- Output: Das Modell gibt den Vektor zurück (z. B. eine Liste mit 1536 Fließkommazahlen).
- Dauer: Dies ist oft der langsamste Teil der Pipeline, abhängig von der Geschwindigkeit der API oder der lokalen GPU.
3. Zusammenfügen des "Data Payload"
In die Datenbank wird nicht nur der Vektor geschrieben. Ein Eintrag in einer Vektordatenbank (oft "Record" oder "Point" genannt) besteht meist aus drei Teilen:
- ID: Eine eindeutige Kennung (UUID).
- Der Vektor: Die Zahlenreihe [0.12, -0.98, ...].
- Metadaten (JSON): Das ist extrem wichtig. Hier speichert man den Originaltext, die Quelle (z. B. "Seite 12, Handbuch.pdf"), den Autor oder das Datum. Ohne Metadaten wüsste die Datenbank später zwar, dass ein Vektor passt, könnte Ihnen den Text aber nicht anzeigen.
4. Indizierung (Indexing) – Der Schreibvorgang
Jetzt werden die Daten tatsächlich in die Datenbank "geschrieben" (oft als Upsert bezeichnet – Update/Insert). Anders als bei SQL, wo die Zeile einfach unten angehängt wird, muss die Vektordatenbank den neuen Vektor in ihren mathematischen Index einsortieren.
- Mapping: Die Datenbank schaut sich den neuen Vektor an und berechnet, wo er im hochdimensionalen Raum liegt.
- Graph-Update (bei HNSW): Wenn ein HNSW-Index verwendet wird, muss die Datenbank Verbindungen (Kanten) zu den nächstgelegenen Nachbarn ziehen. Der neue Punkt wird also sofort in das "Straßennetz" der bestehenden Daten integriert.
- Aufwand: Das ist rechenintensiv. Deshalb unterstützen viele Vektordatenbanken (wie Pinecone oder Weaviate) das asynchrone Indizieren. Die Daten sind erst durchsuchbar, wenn sie in den Index integriert wurden (was meist nur Millisekunden bis Sekunden dauert).
Zusammenfassung am Beispiel
Stellen Sie sich vor, Sie laden eine PDF-Rechnung hoch:
- Extract: Ein Skript extrahiert den rohen Text aus der PDF.
- Chunk: Der Text wird in 3 Absätze geteilt.
- Embed: Die 3 Absätze werden an die KI gesendet -> 3 Vektoren kommen zurück.
- Upsert: Die Datenbank speichert die 3 Vektoren und merkt sich in den Metadaten: "Gehört zu Rechnung_2023.pdf".
- Index: Die Datenbank verknüpft diese Vektoren intern mit anderen Vektoren, die sich um Themen wie "Kosten", "Bezahlung" oder "Steuern" drehen.
Haben Sie vor, eine solche Pipeline selbst zu bauen und benötigen Unterstützung? Dann sprechen Sie uns gerne an.