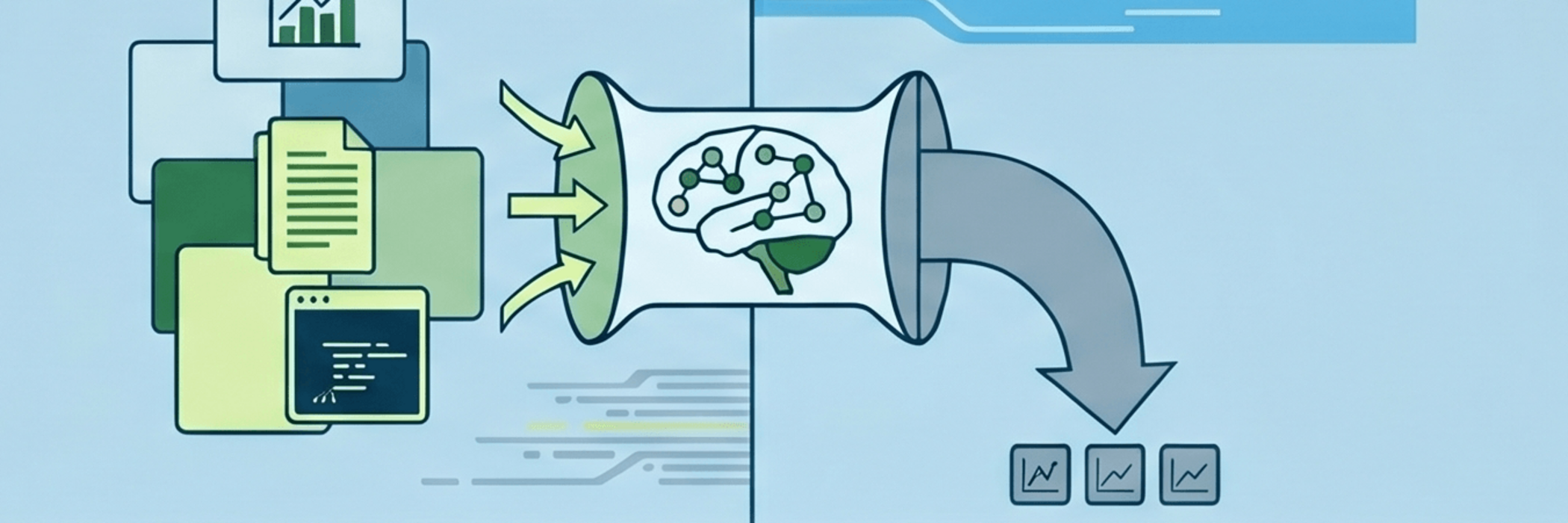
Dokumente bestehen aus Tabellen, Screenshots, Scans, Infografiken und eingebetteten Videos. Hier setzt das von Alibaba veröffentlichte Qwen3-VL-Embedding-8B an: Ein hochmodernes Open-Source-Modell, das Text, Bild- und Videoinhalte nativ in einen einzigen, gemeinsamen Vektorraum überführt.
Mit Platz 1 auf führenden Leaderboards (wie dem MMEB-v2) stellt dieses 8-Milliarden-Parameter-Modell einen technologischen Sprung für visuelle und multimodale Sucharchitekturen dar.
1. Kernspezifikationen auf einen Blick
Qwen3-VL-Embedding-8B basiert auf der fundamentalen Vision-Language-Architektur von Qwen3-VL und bringt folgende Eckdaten mit:
| Feature | Spezifikation |
|---|---|
| Modelltyp | Dual-Tower Multimodal Embedding |
| Parametergröße | 8 Milliarden (8B) |
| Unterstützte Modalitäten | Text, Bilder, Dokumenten-Screenshots, Videos & gemischter Input |
| Sprachunterstützung | Über 30 Sprachen (exzellente Cross-Lingual-Performance) |
| Kontextfenster | Bis zu 32.768 Tokens (32k) |
| Standard-Dimension | Bis zu 4096 (bzw. 3584 nativ im Vision-Modus) |
| Spezialfeatures | Matryoshka Representation Learning (MRL), Custom Instructions |
2. Architektur & Funktionsweise
Traditionelle Ansätze versuchen oft, Bild-Embeddings (z. B. via CLIP) und Text-Embeddings (z. B. via BERT) über lineare Projektionen mühsam aneinander anzupassen. Qwen3-VL-Embedding-8B nutzt stattdessen eine Dual-Tower-Architektur auf Basis eines nativen Vision-Language-Modells.
Funktionsprinzip:
- Multimodaler Input: Das Modell akzeptiert Text-Prompts kombiniert mit visuellen Daten (z. B. "Finde die Umsatzgrafik aus Q3" + ein Bild eines PDF-Berichts).
- Einheitliche Tokenisierung: Visuelle Daten werden über einen hochentwickelten Vision-Encoder in visuelle Tokens zerlegt und sequenziell mit den Text-Tokens verarbeitet.
- [EOS]-Pooling: Um den finalen, semantischen Vektor zu extrahieren, greift das Modell auf den Hidden-State-Vektor des speziellen [EOS]-Tokens (End of Sequence) aus der letzten Layer zurück. Dieser komprimiert die gesamte multimodale Information in einen einzigen Vektor.
- Matryoshka Representation Learning (MRL)
Ein echtes Highlight ist die Unterstützung von MRL. Das bedeutet, dass die wichtigsten semantischen Informationen in den ersten Dimensionen des Vektors konzentriert sind. Entwickler können den Vektor flexibel kürzen (z. B. von 4096 auf 512 oder 256 Dimensionen). Das spart massiv Speicherplatz in Vektordatenbanken (wie pgvector, Milvus oder Qdrant) und Rechenleistung, bei minimalem Verlust der Retrieval-Genauigkeit.
3. Die Trainings-Methodik
Die außergewöhnliche Retrieval-Qualität kommt nicht von ungefähr. Das Modell durchläuft ein ausgeklügeltes, mehrstufiges Trainings-Paradigma:
- Stufe 1: Großflächiges kontrastives Pre-Training: Das Modell lernt anhand von Milliarden Bild-Text-Paaren grundlegende Zuordnungen ("Welcher Text passt zu welchem Bild?").
- Stufe 2: Multimodales Hard-Negative-Training: Hier wird die Trennschärfe geschärft. Das Modell lernt, minimal unterschiedliche Bilder oder Texte sauber voneinander zu unterscheiden.
- Stufe 3: Distillation aus dem Reranker: Das Embedding-Modell wird direkt mithilfe des mächtigeren Qwen3-VL-Reranker-8B (einer Cross-Encoder-Architektur) trainiert. Die feingranularen Relevanz-Scores des Rerankers fließen so als "Wissen" direkt in die Effizienz des Embedding-Modells ein.
4. Benchmark-Performance
In der Praxis dominiert das Modell die gängigen Benchmarks für visuelles und multimodales Retrieval:
- MMEB-v2 (Multimodal Embedding Benchmark): Qwen3-VL-Embedding-8B erzielt einen durchschnittlichen Top-Score von 77.8 und setzt sich damit an die Spitze der Industrie.
- Herausragende Dokumenten-Suche (ViDoRe / JinaVDR): Besonders bei der Suche in gescannten PDFs, Diagrammen und Tabellen (Visual Document Retrieval) deklassiert das Modell klassische, rein textbasierte OCR-Pipelines, da das visuelle Layout der Dokumente nativ verstanden wird.
5. Optimaler Einsatz: Das "Two-Stage-Retrieval" Pattern
Um das volle Potenzial in einer realen Anwendung (z. B. einer unternehmensweiten multimodalen Wissensdatenbank) auszuschöpfen, empfiehlt sich das Zusammenspiel mit dem Schwestermodell Qwen3-VL-Reranker-8B:
- Stage 1 (Recall mit Embedding): Qwen3-VL-Embedding-8B wandelt Millionen von Dokumentenseiten und Bildern in Vektoren um. Bei einer User-Anfrage filtert die Vektordatenbank blitzschnell die Top 50 relevantesten Kandidaten heraus.
- Stage 2 (Reranking mit Reranker): Der Qwen3-VL-Reranker-8B analysiert die Top 50 Kandidaten mittels Cross-Attention im Detail paarweise und liefert ein hochpräzises, finales Relevanz-Ranking (Sortierung nach "Yes/No"-Wahrscheinlichkeit).
Fazit
Das Qwen3-VL-Embedding-8B schließt die Lücke zwischen Bildverarbeitung und Textsuche auf Enterprise-Niveau. Für Entwickler, die RAG-Systeme für komplexe PDFs, Dashboards oder Videoarchive bauen, führt an diesem 8B-Modell derzeit kaum ein Weg vorbei. Es vereint die Mächtigkeit moderner Vision-LLMs mit der Effizienz hochentwickelter Vektor-Embeddings.