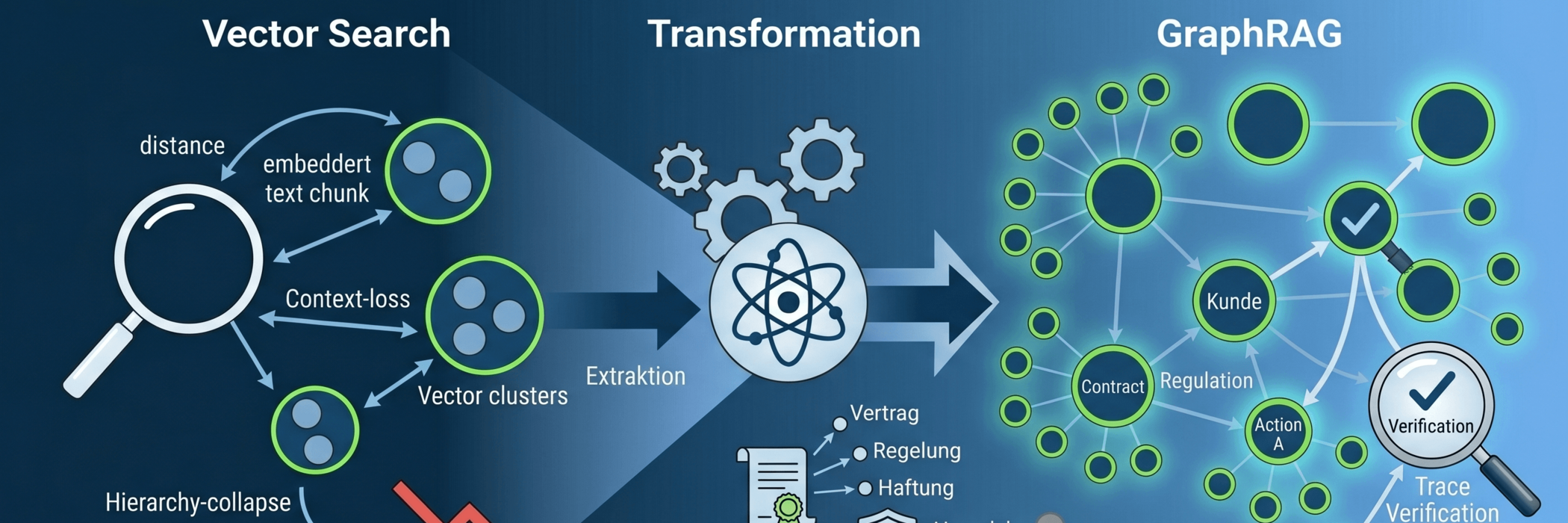
Wenn es jedoch um produktive, geschäftskritische Systeme geht, merken wir in der technischen Praxis immer häufiger, dass der Standard-Ansatz über reine Vektordatenbanken an eine gläserne Decke stößt. Das fundamentale Problem dabei: Rein mathematische Ähnlichkeitssuchen messen eben nur die Nähe von Begriffen, nicht deren formallogische Korrektheit. In der berüchtigten „Cosinus-Falle“ liegen für eine Vektordatenbank die Aussagen „Aktion A ist unter Bedingung X erlaubt“ und „Aktion A ist unter Bedingung X strengstens untersagt“ fatal nah beieinander, weil sie fast identische Vokabeln nutzen.
In unserem neuen Whitepaper habe wir uns intensiv mit der Architektur-Evolution beschäftigt, die wir jetzt für echte Gewissheit im Enterprise-Einsatz brauchen: dem Wechsel zu GraphRAG und temporalen Kontext-Graphen.
- Uns ging es beim Verfassen ganz bewusst nicht darum, den nächsten KI-Hype zu befeuern, sondern eine nüchterne, substanzorientierte Analyse für Entscheider und Architekten vorzulegen:
- Wann reicht klassisches RAG aus? Wenn die Aufgabe im Auffinden isolierter Dokumente (wie FAQs oder HR-Handbücher) besteht, sind optimierte Vektorsuchen oft völlig ausreichend.
- Wann wird ein Wissensgraph zwingend? Sobald Abfragen eine echte Aggregationsleistung und das Verknüpfen logischer Kausalitäten über mehrere Dokumentenhierarchien hinweg verlangen.
- Welcher Stack passt zu Ihrer Infrastruktur? Wir vergleichen den integrierten Multi-Model-Ansatz (z. B. PostgreSQL + pgvector + Apache AGE) mit dedizierten Hybrid-Stacks (z. B. Neo4j).
- Wo liegen die echten Implementierungsrisiken? Ein Graph ist kein inhärent fehlerfreies Allheilmittel. Seine Qualität steht und fällt mit der Extraktionspräzision kleinerer KI-Modelle und der datentechnischen Herausforderung der konsistenten Entitätsauflösung.
Wie lösen wir chronologische Konflikte? Wissen in dynamischen Märkten hat eine Halbwertszeit. Wenn Richtlinien oder Verträge sich ändern, benötigen wir zwingend Zeitvektoren auf Datenbankebene, um historische Anachronismen algorithmisch zu eliminieren.
Unser zentrales Fazit
Wir minimieren Halluzinationen in komplexen Enterprise-Umgebungen nicht primär durch den Einsatz immer größerer Sprachmodelle, sondern durch eine überlegene, zeitsensitive Datenarchitektur. Nur so schaffen wir ein transparentes, logisch nachvollziehbares digitales Gedächtnis als Fundament für verlässliche Entscheidungen. Das vollständige Dokument „Beyond Vector Search: Die Evolution zu GraphRAG und temporalen Kontext-Graphen“ steht ab sofort für Sie bereit.
Download Whitepaper “Whitepaper_GraphRAG_Kettel_rms”