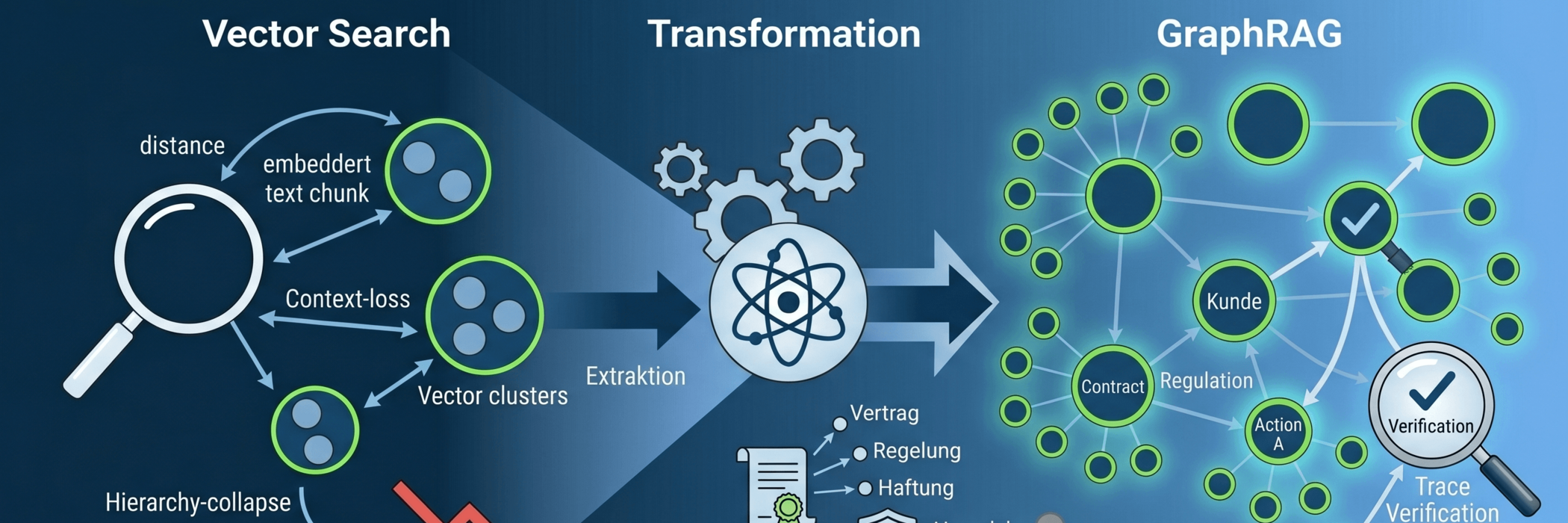
However, when it comes to productive, business-critical systems, we are increasingly finding in technical practice that the standard approach of relying solely on vector databases has reached its limits. The fundamental problem here is that purely mathematical similarity searches merely measure the proximity of terms, not their formal logical correctness. In the notorious ‘cosine trap’, the statements ‘Action A is permitted under condition X’ and ‘Action A is strictly prohibited under condition X’ lie dangerously close together for a vector database, because they use almost identical vocabulary.
In our new white paper, we have taken an in-depth look at the architectural evolution we now need to achieve true certainty in enterprise deployment: the shift to GraphRAG and temporal context graphs.
- In writing this, we were deliberately not aiming to fuel the next AI hype, but rather to present a sober, substance-oriented analysis for decision-makers and architects:
- When is classic RAG sufficient? If the task involves finding isolated documents (such as FAQs or HR manuals), optimised vector searches are often entirely sufficient.
- When does a knowledge graph become essential? As soon as queries require genuine aggregation capabilities and the linking of logical causalities across multiple document hierarchies.
- Which stack suits your infrastructure? We compare the integrated multi-model approach (e.g. PostgreSQL + pgvector + Apache AGE) with dedicated hybrid stacks (e.g. Neo4j).
- Where do the real implementation risks lie? A graph is not an inherently error-free panacea. Its quality stands or falls with the extraction precision of smaller AI models and the data-technical challenge of consistent entity resolution.
How do we resolve chronological conflicts? Knowledge in dynamic markets has a half-life. When policies or contracts change, we urgently need time vectors at the database level to algorithmically eliminate historical anachronisms.
Our key conclusion
We minimise hallucinations in complex enterprise environments not primarily through the use of ever-larger language models, but through a superior, time-sensitive data architecture. Only in this way can we create a transparent, logically traceable digital memory as the foundation for reliable decisions. The full document “Beyond Vector Search: The Evolution to GraphRAG and Temporal Context Graphs” is now available.
Download white paper “Whitepaper_GraphRAG_Kettel_rms”