Doch wer Vektordatenbanken im produktiven Enterprise-Einsatz skaliert, stößt schnell auf ein Phänomen, das im Hintergrund und völlig lautlos auftritt: Die Qualität der Suchergebnisse nimmt im Laufe der Zeit ab, während gleichzeitig die Latenzzeiten steigen. Das System leidet unter einer schleichenden Degradierung.
Das mathematische Dilemma: Warum Vektorsuchen nicht „statisch“ sind
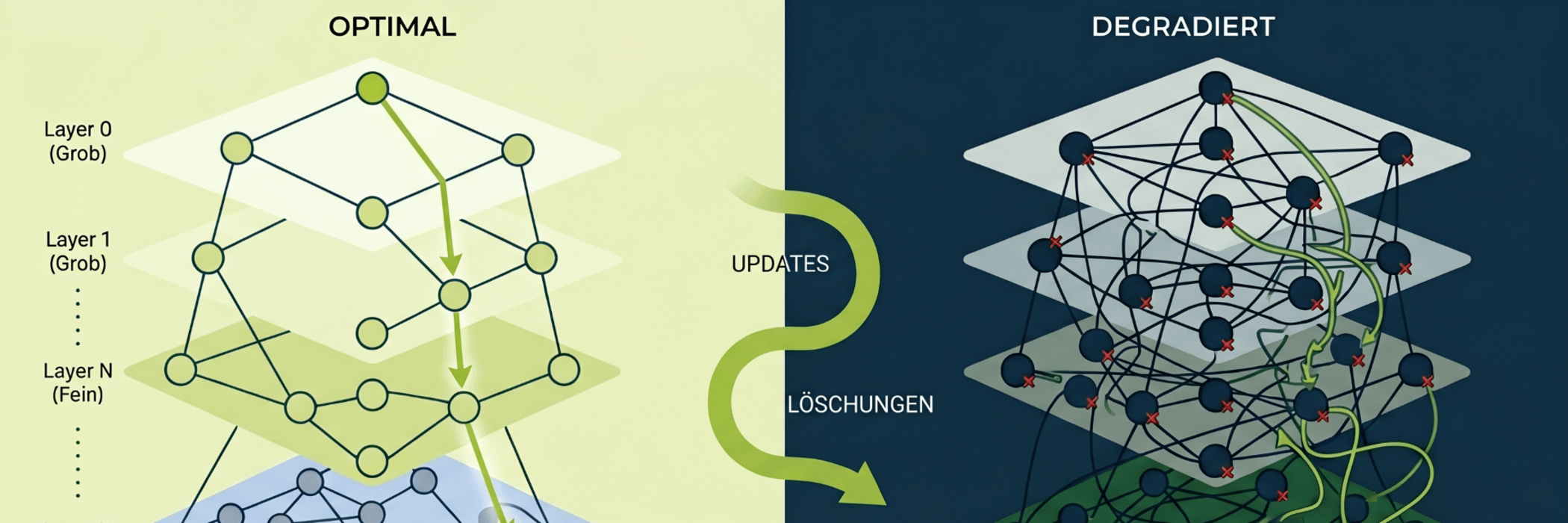
Um zu verstehen, warum die Suchqualität (die sogenannte Recall Rate) sinkt, muss man einen Blick auf die zugrunde liegende Technik werfen. Bei Millionen von hochdimensionalen Vektoren ist eine exakte Berechnung der nächsten Nachbarn (Brute-Force-Suche) rechentechnisch zu teuer. Vektordatenbanken nutzen daher Algorithmen für die annähernde Nachbarschaftssuche (Approximate Nearest Neighbor, ANN).
Der am weitesten verbreitete Algorithmus ist HNSW (Hierarchical Navigable Small World). HNSW baut eine mehrschichtige Graphenstruktur auf, bei der Vektoren als Knoten miteinander vernetzt sind. Die Suche navigiert ähnlich wie bei einem Verkehrsnetz von groben, weitmaschigen Schichten hinab zu den feinen, engmaschigen Nachbarschaften.
Das Problem: HNSW und ähnliche mathematische Graphenstrukturen wurden primär für statische Datensätze entwickelt. Einmal aufgebaut, performen sie exzellent. Ein produktives System lebt jedoch von kontinuierlichen Veränderungen.
Der technische Prozess der Index-Degradierung
Wenn ein System im Live-Betrieb ständig Daten aufnimmt, verändert oder entfernt, gerät die geometrische Balance des Index aus den Fugen. Drei technische Prozesse treiben diese Verschlechterung voran:
- Strukturelle Degenerierung durch kontinuierliche Inserts
Neue Vektoren werden fortlaufend in den bestehenden Graphen eingefügt. Der Algorithmus verknüpft die neuen Knoten mit den aktuell besten Nachbarn. Allerdings optimiert er die Pfade der bereits existierenden Knoten meist nicht rückwirkend. Mit der Zeit erodiert die Navigierbarkeit des Graphen. Die Suchpfade werden länger, verwinkelter und ineffizienter. - Das Problem der „Tombstones“ bei Löschungen
Das echte, physikalische Löschen eines Vektors aus einem HNSW-Graphen ist hochkomplex, da es die Verbindungen im Netzwerk zerreißen und ganze Regionen isolieren würde. Die meisten Vektordatenbanken nutzen daher „Soft Deletes“ (sogenannte Tombstones). Ein gelöschter Vektor wird lediglich als ungültig markiert. Er verbleibt jedoch im Graphen, damit der Suchalgorithmus ihn weiterhin als „Brücke“ nutzen kann.
Sammeln sich diese Datenleichen an, springt der Suchalgorithmus bei Abfragen über unzählige tote Knoten. Das kostet CPU-Zyklen sowie RAM, erhöht die Latenz massiv und verfälscht die logische Nachbarschaftsauswahl. - Data Drift und veränderte Datenverteilung
Ein ANN-Index wird auf Basis der Datenverteilung zum Zeitpunkt seiner Erstellung optimiert. Ändern sich die Inhalte – etwa weil ein E-Commerce-Shop neue Produktkategorien einführt oder sich die Themen in einem Support-Bot verlagern –, passen die voreingestellten Index-Parameter (wie die Pfadlänge ef oder die Verbindungsdichte M) nicht mehr zur neuen Datenrealität. Die Recall Stability bricht ein.
Was man dagegen tun kann: Strategien für die Praxis
Um dieser schleichenden Verschlechterung entgegenzuwirken, müssen Betriebsteams Vektordatenbanken als dynamische Systeme begreifen und proaktiv managen:
- Regelmäßiges „Vacuuming“: Es sollten Prozesse aufgesetzt werden, die verwaiste Tombstones physisch entfernen und die betroffenen Graphenkanten gezielt reparieren.
- Recall-Monitoring etablieren: Die Überwachung von CPU und Speicher reicht nicht aus. Es sollte zyklisch eine automatisierte Stichprobe durchgeführt werden, bei der die Ergebnisse der ANN-Suche mit einer exakten Brute-Force-Suche auf einem Test-Set verglichen werden. Sinkt die Übereinstimmung unter einen Schwellenwert (z.B. 90%), besteht Handlungsbedarf.
- Segmentierte Index-Architekturen: Große Indizes können in Hot-, Warm- und Cold-Segmente unterteilt werden. Neue Daten fließen in kleine, hochperformante In-Memory-Segmente, die sich schnell optimieren lassen, während historische Daten komprimiert (z.B. mittels Product Quantization) im Cold-Storage verbleiben.
Fazit
Eine Vektordatenbank ist kein System nach dem Prinzip „Set-it-and-forget-it“. Wer auf kontinuierliche Daten-Updates angewiesen ist, muss die mathematische Alterung des Index einkalkulieren, um ungenaue KI-Antworten und Performance-Einbrüche zu verhindern.
Bei rms. lösen wir genau dieses Problem für unsere Enterprise-Kunden und KI-Hub-Infrastrukturen systematisch: Wir implementieren automatisierte Wartungszyklen, die den Vektor-Index in fest definierten Intervallen vollständig neu aufbauen. Durch diesen regelmäßigen Refresh werden struktureller Ballast und Tombstones restlos beseitigt, die Graphen-Pfade mathematisch neu optimiert und eine dauerhaft maximale Suchpräzision sowie minimale Latenz im RAG-Betrieb garantiert.