However, anyone scaling vector databases for production use in an enterprise environment will soon encounter a phenomenon that occurs in the background, completely silently: the quality of search results deteriorates over time, whilst latency increases. The system suffers from a gradual degradation.
The mathematical dilemma: why vector searches are not ‘static’
To understand why search quality (the so-called recall rate) declines, one must take a look at the underlying technology. With millions of high-dimensional vectors, an exact calculation of the nearest neighbours (brute-force search) is computationally too expensive. Vector databases therefore use algorithms for approximate nearest neighbour (ANN) search.
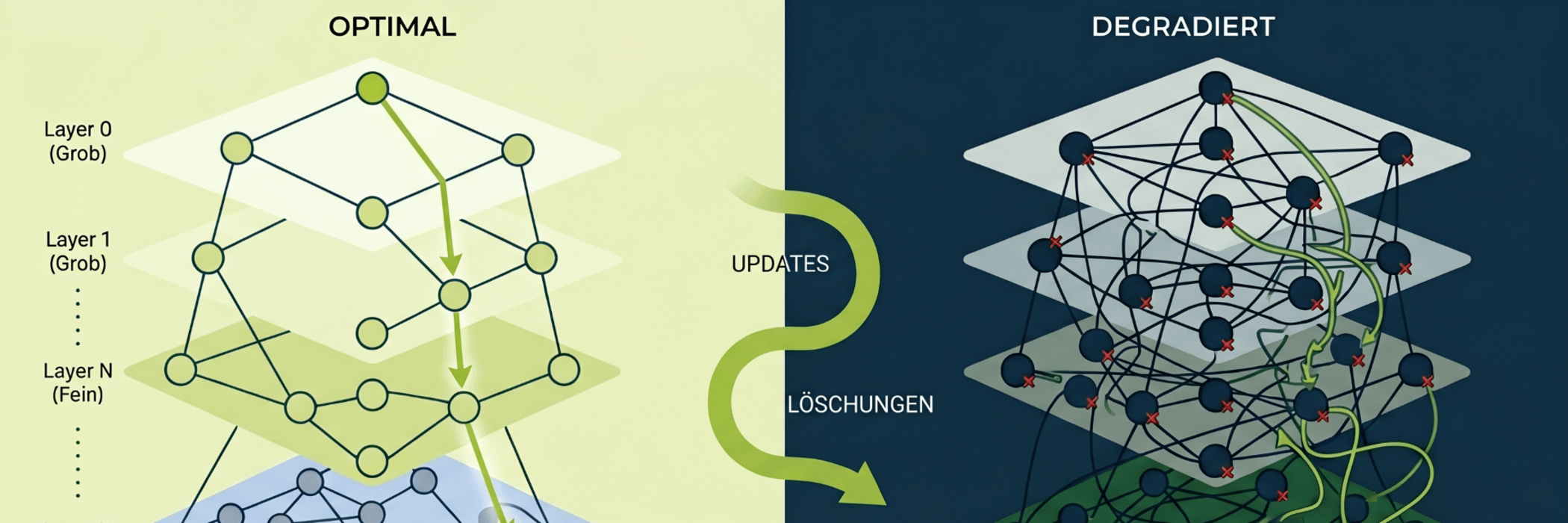
The most widely used algorithm is HNSW (Hierarchical Navigable Small World). HNSW constructs a multi-layered graph structure in which vectors are interconnected as nodes. The search navigates, much like a transport network, from coarse, wide-mesh layers down to the fine, tight-mesh neighbourhoods.
The problem: HNSW and similar mathematical graph structures were primarily developed for static datasets. Once established, they perform excellently. However, a production system thrives on continuous change.
The technical process of index degradation
When a system in live operation constantly adds, modifies or removes data, the geometric balance of the index is thrown off balance. Three technical processes drive this degradation:
- Structural degeneration due to continuous inserts
New vectors are continuously inserted into the existing graph. The algorithm links the new nodes to their current best neighbours. However, it usually does not optimise the paths of the existing nodes retrospectively. Over time, the navigability of the graph erodes. The search paths become longer, more convoluted and less efficient. - The problem of ‘tombstones’ during deletions
The actual, physical deletion of a vector from an HNSW graph is highly complex, as it would sever connections in the network and isolate entire regions. Most vector databases therefore use ‘soft deletes’ (so-called tombstones). A deleted vector is merely marked as invalid. However, it remains in the graph so that the search algorithm can continue to use it as a ‘bridge’.
If these data ‘corpses’ accumulate, the search algorithm skips over countless dead nodes during queries. This consumes CPU cycles and RAM, massively increases latency, and distorts the logical neighbourhood selection. - Data drift and changing data distribution
An ANN index is optimised based on the data distribution at the time of its creation. If the content changes – for example, because an e-commerce shop introduces new product categories or the topics in a support bot shift – the pre-set index parameters (such as the path length ef or the connection density M) no longer match the new data reality. Recall stability collapses.
What can be done about it: practical strategies
To counteract this creeping deterioration, operations teams must view vector databases as dynamic systems and manage them proactively:
- Regular ‘vacuuming’: Processes should be set up to physically remove orphaned tombstones and specifically repair the affected graph edges.
- Establish recall monitoring: Monitoring CPU and memory is not sufficient. An automated sample check should be carried out cyclically, comparing the results of the ANN search with an exact brute-force search on a test set. If the match rate falls below a threshold (e.g. 90%), action is required.
- Segmented index architectures: Large indexes can be divided into hot, warm and cold segments. New data flows into small, high-performance in-memory segments that can be optimised quickly, whilst historical data remains in cold storage in a compressed form (e.g. using product quantisation).
Conclusion
A vector database is not a ‘set-it-and-forget-it’ system. Anyone reliant on continuous data updates must factor in the mathematical ageing of the index to prevent inaccurate AI responses and performance drops.
At rms., we systematically solve precisely this problem for our enterprise clients and AI hub infrastructures: we implement automated maintenance cycles that completely rebuild the vector index at fixed intervals. This regular refresh completely eliminates structural overhead and tombstones, mathematically re-optimises the graph paths, and guarantees consistently maximum search precision and minimal latency in RAG operations.